
import pandas as pd
import statsmodels.formula.api as smf
col = [
'target', 'B', 'C', 'D', 'E', 'F', 'G'
]
raw_df = pd.read_csv("data.csv", sep=",", skiprows=1, header=None)
print(type(raw_df))
data = pd.DataFrame(raw_df.values, columns=col)
print(data)
mod = smf.ols(formula='target~B+C+D+E+F+G', data=data)
res = mod.fit()
print(res.summary())其中,target是因变量Y,B,C等是因数x。
数据格式如下:
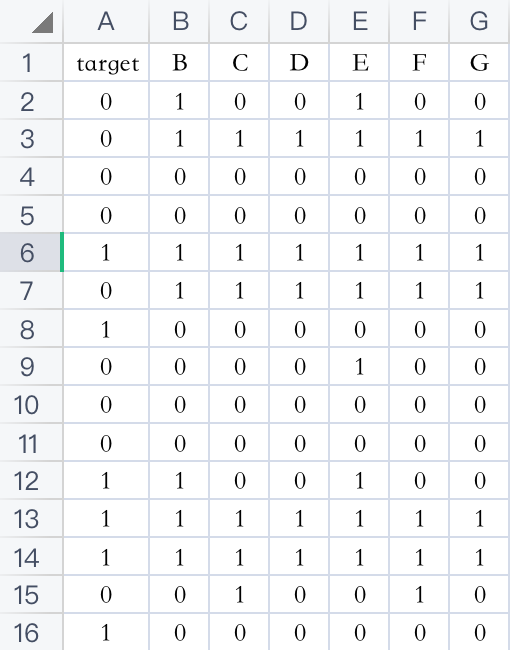
输出结果:

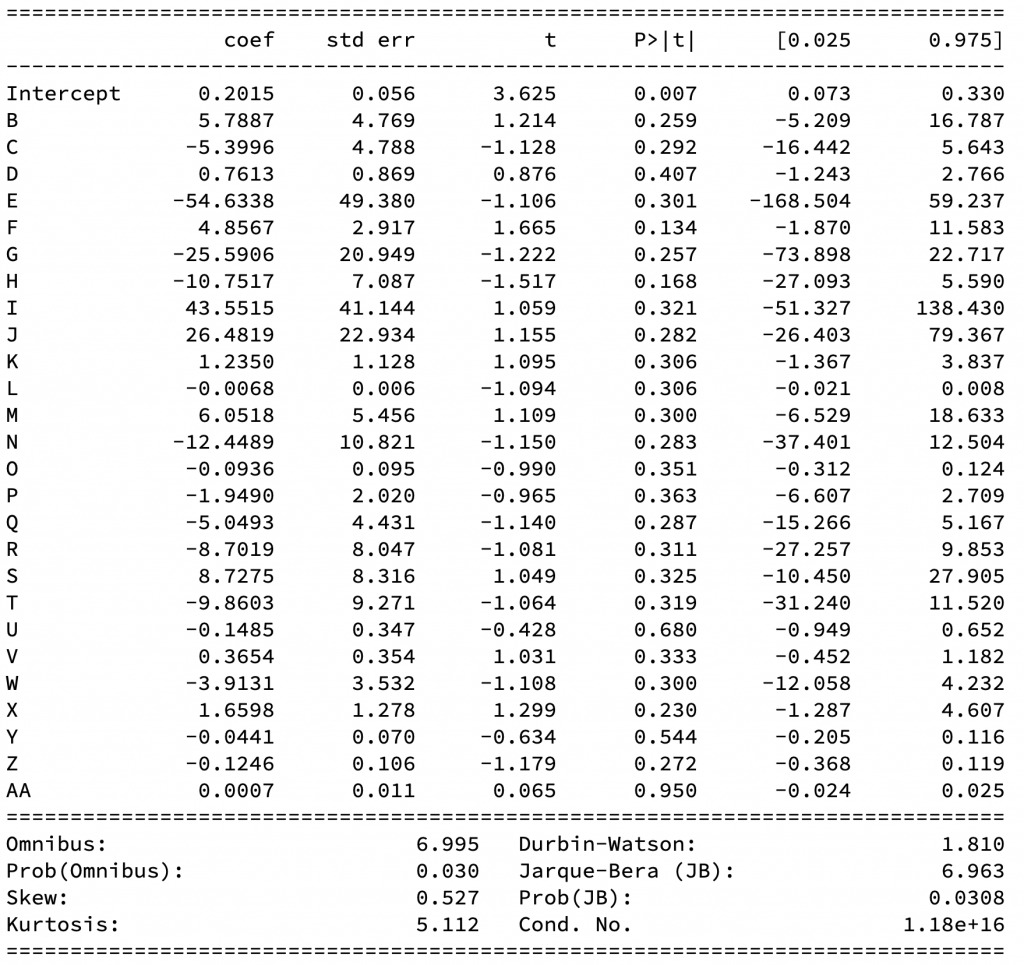
模型解释:
t:t 统计量(t-Statistic),等于回归系数除以标准差,用于对每个回归系数分别进行检验,检验每个自变量对因变量的影响是否显著。如果某个自变量 xi的影响不显著,意味着可以从模型中剔除这个自变量。
P>|t|:t检验的 P值(Prob(t-Statistic)),反映每个自变量 xi 与因变量 y 的相关性假设的显著性。如果 p<0.05,可以理解为在0.05的显著性水平下变量xi与y存在回归关系,具有显著性。
[0.025,0.975]:回归系数的置信区间(Confidence interval)的下限、上限,某个回归系数的置信区间以 95%的置信度包含该回归系数 。注意并不是指样本数据落在这一区间的概率为 95%。
R-squared:R方判定系数(Coefficient of determination),表示所有自变量对因变量的联合的影响程度,用于度量回归方程拟合度的好坏,越接近于 1说明拟合程度越好。
F-statistic:F 统计量(F-Statistic),用于对整体回归方程进行显著性检验,检验所有自变量在整体上对因变量的影响是否显著。